In dieser Hausaufgabe nutzen wir Daten aus der Bildungsstatistik des Kantons Zürich und werden diese mit uns bekannten Werkzeugen erkunden und visualisieren.
Ziele
Diese Hausaufgabe hat die folgenden Ziele:
- Erfahrungen mit den Hauptfunktionen des
{dplyr}Package sammeln - Die Elemente einer vorgegebenen `{ggplot2}´ Visualisierung zu identifizieren und diese zu rekunstrieren
Erste Schritte
Öffne deine Email Inbox und suche nach der Email mit dem Link für das GitHub Repo zu dieser Hausaufgabe (ha-04-mehr-dplyr). Alternativ kannst du GitHub öffnen und in unserer GitHub Organisation nach dem Repo mit deinem Namen suchen.
Folge den Schritten aus Hausaufgabe 1 oder den Folien der Woche 2 um das GitHub Repo in deine RStudio Cloud zu clonen.
Packages
In dieser Hausaufgabe werden wir weiterhin hauptsächlich das R Package {dplyr} aus der Sammlung der {tidyverse} Packages nutzen. Zusätzlich nutzen wir vereinzelt Funktionen aus R Packages, welche du noch nicht kennegelernt hast.
Data
Übersicht über alle Lernenden im Kanton Zürich
Ein Datensatz publiziert von der Bildungsstatitik Kanton Zürich. Der Datensatz ist öffentlich auf opendata.swiss verfügbar und wird auch auf einer Seite der Bildungsstatistik selbst mit Visualisierungen dargestellt.
Aufwärmen
- Öffne die R Markdown Datei für die Übung
- Stricke die Datei zu einer HTML Datei
- Aktualisiere den YAML Header in dem du deinen Namen und das Datum hinzufügst
- Passe das Aussehen des Dokuments über die “Output Options” an
- Stricke das Dokument erneut
🧶 ✅ ⬆️ Knit, commit und push deine Änderungen auf GitHub mit einer Commit-Nachricht deiner Wahl. Achte darauf, alle geänderten Dateien zu committen und zu pushen, damit dein Git-Fenster danach aufgeräumt ist.
Übungen - Lernende im Kanton Zürich
Übung 1 - Daten Importieren
Ich habe die Daten für dich bereits importiert, auf das Jahr 2019 eingeschränkt und die NAs entfernt. Wir werden in allen folgenden Übungen, bis auf Übung 6 dem Objekt lernende2019 arbeiten.
# Der Link zu den Daten wird hier als Objekt gespeichert
# und taucht oben rechts in deinem "Environment" auf
link <- "https://www.web.statistik.zh.ch/ogd/data/bista/ZH_Uebersicht_alle_Lernende.csv"
# Hier wird nun das Objekt "link" genutzt um die CSV zu lesen
lernende <- read_csv(file = link)Übung 2 - Daten beschreiben
In dieser Übung geht es darum die Daten zu erkunden und zu beschreiben. Dazu schauen wir uns auch nochmals die Variablen Typen innerhalb des Dataframes lernende2019 an.
Variablen können ganz allgemein in numerische und nicht-numerische unterteilt werden. Innerhalb der numerischen Variablen, wird zwischen diskreten und kontinuierlichen Variablen unterschieden.
Diskrete Variablen sind numerische Variablen, die zwischen zwei beliebigen Werten eine zählbare Anzahl von nicht negativen Werten aufweisen. Eine diskrete Variable ist immer numerisch. Beispiele: Die Anzahl Schüler in der Primarschule oder das Ergebnis eines Wurfs eines Würfels.
Stetige (kontinuierliche) Variablen sind numerische Variablen, die zwischen zwei beliebigen Werten eine unendliche Anzahl von Werten aufweisen. Stetige Variablen können aus numerischen oder Datums-/Uhrzeitwerten bestehen. Beispiel: die Länge eines Teils oder Datum und Uhrzeit eines Zahlungseingangs
Nicht-numerische Variablen werden auch als kategoriale Variablen bezeichnet.
Kategoriale Variablen umfassen eine endliche Anzahl von Kategorien oder eindeutigen Gruppen. Kategoriale Daten müssen nicht zwangsläufig eine logische Reihenfolge aufweisen (z.B. Materialtyp, Zahlungsmethode, Automarke). Wenn die Daten eine logische Reihenfolge aufweisen, dann werden sie auch als ordinal bezeichnet (z.B. Wochentage, Schulnoten).

Die Fragen für diese Übungen sind in der Vorlage für die Hausaufgabe hinterlegt.
Übung 3 - Daten visualisieren
Ich habe hier einen Plot mit dem Dataframe lernende2019 vorbereitet. In dieser Übung geht es darum, dass du die einzelnen Elemente des Plots (x-Achse, y-Achse, etc.) studierst und versuchst den Plot selnst zu rekonstruieren.
Tipp: Nutze geom_col() und nicht geom_bar()
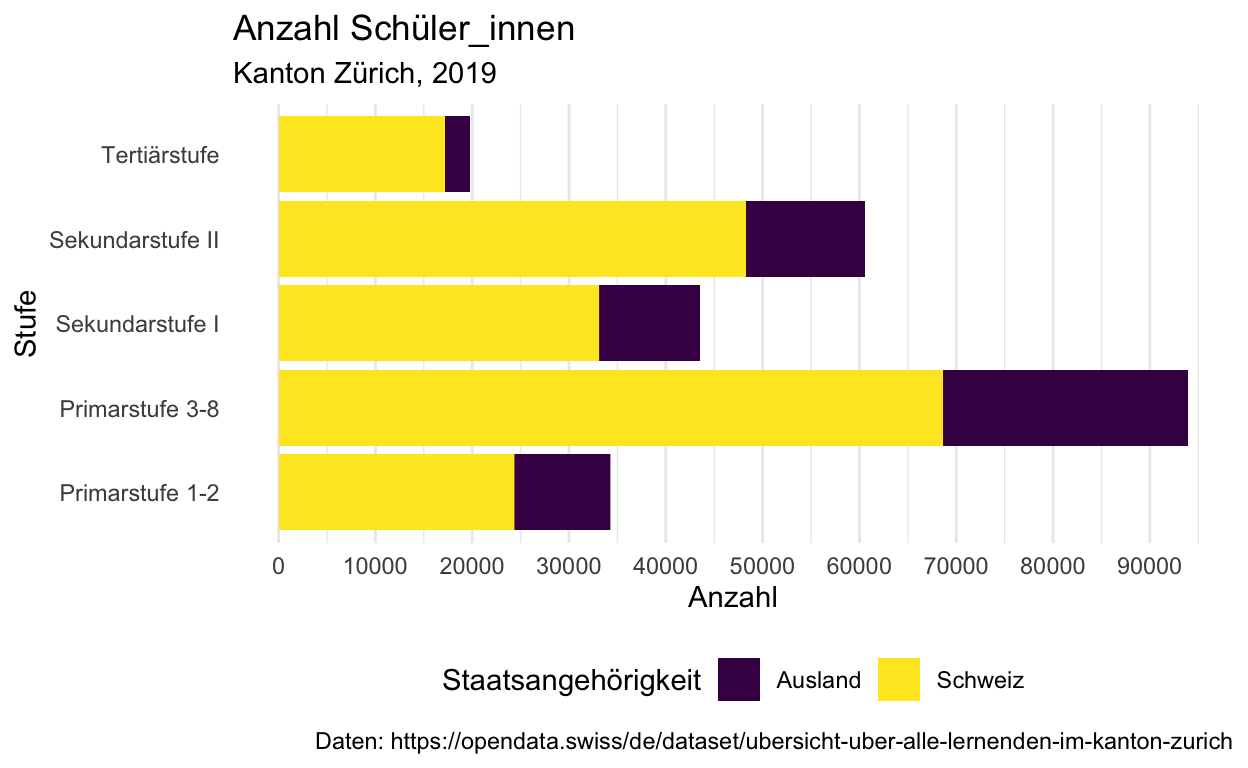
Übung 4 - Daten eingrenzen
Die Übung ist in der Vorlage für die Hausaufgabe beschrieben.
Übung 5 - Daten zusammenfassen
In den folgenden zwei Code-chunks findest du jeweils eine Code Sequenz, welche eine Häufigkeitstabelle mit den Spalten Schultyp und n erstellt.
Versuche den Code so anzupassen dass du folgendes Ergebnis erreichst:
# A tibble: 6 × 2
Schultyp n
<chr> <dbl>
1 Berufsfachschule 45532
2 Brückenangebot 2078
3 Heim- und Sonderschule 3021
4 Höhere Berufsbildung 19780
5 Mittelschule 20591
6 Volksschule 161072Übung 6 - Kurzanalyse
Der Code für diese Aufgabe ist vorbereitet. Es geht hier darum die Lücken auszufüllen. Jede Lücke hat einen Platzhalter mit drei Unterstrichen ___, unabhänig davon wie viele Zeichen ersetzt werden sollen. Die Beschreibung der einzelnen Schritte ist in der Vorlage für die Hausaufgabe.
lernende ___
drop____ %>%
group_by(___) %>%
summarise(
Total = ___(___)
) %>%
mutate(
Differenz = Total - ___(Total)
) %>%
mutate(
Veraenderung = case_when(
Differenz > ___ ~ "Zunahme",
Differenz < ___ ~ "Abnahme"
)
)🧶 ✅ ⬆️ Knit, commit und push deine Änderungen auf GitHub mit einer Commit-Nachricht deiner Wahl. Achte darauf, alle geänderten Dateien zu committen und zu pushen, damit dein Git-Fenster danach aufgeräumt ist.