Das Portal opendata.swiss stellt der Allgemeinheit offene Behördendaten in einem zentralen Katalog zur Verfügung. Es wird betrieben vom Bundesamt für Statisik und ist ein gemeinsames Projekt von Bund, Kantonen, Gemeinden und weiteren Organisationen mit einem staatlichen Auftrag. In dieser Hausaufgabe nutzen wir den Datensatz “Corona Hilfen im Kulturbereich im Kanton Zürich” publiziert am 04. März 2021 von der Fachstelle Open Government Data des Kantons Zürich, und der Fachstele Kultur der Direktion der Justiz und des Innern.
Ziele
Diese Hausaufgabe hat die folgenden Ziele:
- einen OGD Datensatz von opendata.swiss zu erkunden
- Visualisierungen zu rekonstruieren
- Mehr Übung mit Git und GitHub zu bekommen
Erste Schritte
Öffne deine Email Inbox und suche nach der Email mit dem Link für das GitHub Repo zu dieser Hausaufgabe (ha-02-hallo-ogd). Alternativ kannst du GitHub öffnen und in unserer GitHub Organisation nach dem Repo mit deinem Namen suchen.
Folge den Schritten aus Hausaufgabe 1 oder den Folien der Woche 2 um das GitHub Repo in die Posit Cloud zu clonen.
Packages
In dieser Hausaufgabe lernst du ein zwei R Packages kennen, welche wir in Woche 3 in mehr Detail behandeln werden. Das {readr} und das {dplyr} Package, welche beide zur Sammlung der {tidyverse} Packages gehören.
Data
Wir nutzen den Datensatz mit dem Titel “Corona Hilfen im Kulturbereich im Kanton Zürich” publiziert am 04. März 2021 von der Fachstelle Open Government Data des Kantons Zürich, Fachstele Kultur (Direktion der Justiz und des Innern).
Die Beschreibung der Variablen ist auf der Ressource für den Datensatz zu finden:
- Kategorie = Antragstellende Kategorie (‘Kulturschaffende’, ‘Kulturunternehmen gemeinnützig’ oder ‘Kulturunternehmen gewinnorientiert’)
- Sparte = Kultursparte (‘Bereichsübergreifend’, ‘Bildende Kunst’, ‘Design’, ‘Film’, ‘Kino’, ‘Klubs und Konzertlokale’, ‘Literatur’, ‘Museen’, ‘Musik’ oder ‘Tanz/Theater’)
- Nachgefragt = Nachgefragter Betrag in CHF (gerundet auf 100 CHF)
- Beschluss = Beschlossener Betrag in CHF (gerundet auf 100 CHF, ‘NA’ bei Ablehnung)
- Status = Status des Antrags (‘Ablehnung’, ‘Ausbezahlt’ oder ‘Saldo offen’)
- Eingangsdatum = Datum des Eingangs des Gesuchs; ‘Beschlussdatum’ = Datum des Beschlusses über das Gesuch
- ID = anonymisierter Identifikator der antragstellenden natürlichen oder juristischen Person
Übungen
Übung 1
Erinnerst du dich, dass RStudio in vier Bereiche unterteilt ist? Versuche diese, ohne nachzuschauen, zu benennen.
Aufgaben
- Füge deine Antworten zu der R Markdown Datei für die Hausaufgabe hinzu
- Stricke das Dokument und verifiziere, dass es keine Fehlermeldung gibt
🧶 ✅ ⬆️ Knit, commit, und pushe deine Änderungen auf GitHub mit der Commit-Nachricht “Füge Antwort für Übung 1 hinzu.” Achte darauf, alle geänderten Dateien zu committen und zu pushen, damit dein Git-Fenster danach aufgeräumt ist.
Übung 2
Verifiziere, dass der Datensatz corona_kultur in deinem Environment (Fenster oben rechts) in RStudio zu finden ist. Wieviele Beobachtungen gibt es in diesem Datensatz?
Aufgaben
- Im RStudio Environment, klicke auf den Namen das Datensatzes
corona_kultur - Führe den Code
View(corona_kultur)in der Console aus. - Nutze die Funktionen
glimpse()undstr()in einem R Code-chunk um die Daten zu erkunden - Führe das Objekt
corona_kulturin der Console aus? Kannst du die Anzahl Reihen und Spalten im Output finden? - Welche zwei weiteren Funktionen kennst du um die Anzahl der Reihen und Spalten eines Datensatzes zu erfahren?
- In der Spalte
Beschlusstaucht immer wieder der Wert ‘NA’ auf. Was bedeutet dies? Generell, und für diesen Datensatz?
🧶 ✅ ⬆️ Knit, commit, und pushe deine Änderungen auf GitHub mit der Commit-Nachricht “Füge Antwort für Übung 2 hinzu.” Achte darauf, alle geänderten Dateien zu committen und zu pushen, damit dein Git-Fenster danach aufgeräumt ist.
Übung 3
Schauen wir uns zuerst die Verteilung der Beträge an, welche nachgefragt wurden. Wir sehen, dass eine grosse Anzahl an kleineren Beträgen (< 100’000 CHF) beantragt wurde, und das einige grosse Beträge (> 2’000’000 CHF) bentragt wurden. Ein Antrag mit über 10 Millionen CHF sticht ganz besonders heraus und führt dazu, dass dieser Plot nicht besonders schön ist.
Code vorlesen: Nutze das Objekt corona_kultur und plotte ein Histogram mit der der Verteilung der nachgefragten Beträge auf der x-Achse. Zähle die Anzahl der Gesuche pro 100’000 CHF auf der y-Achse.
ggplot(data = corona_kultur, aes(x = Nachgefragt)) +
geom_histogram(binwidth = 100000)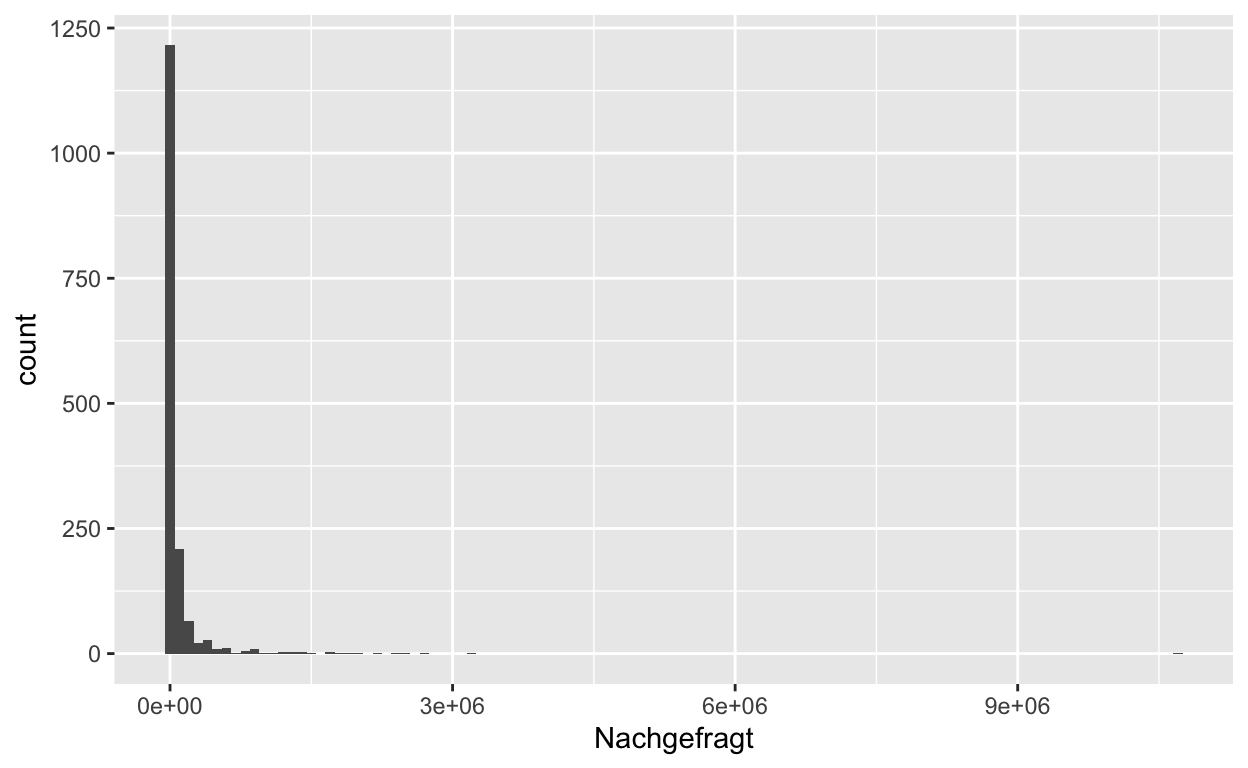
Code vorlesen: Beginne mit dem Objekt corona_kultur und leite es in die Funktion filter(), um nach Beobachtungen zu filtern, bei denen die Variable ‘Nachgefragt’ grösser 2’000’000 ist. Ordne den Datensatz dann in absteigender Reihenfolge nach der Variable ‘Nachgefragt’
# A tibble: 9 × 8
Kategorie Sparte Nachgefragt Beschluss Status Eingangsdatum
<chr> <chr> <dbl> <dbl> <chr> <date>
1 Kulturunternehmen… Kino 10749500 2531400 Ausbe… 2020-11-30
2 Kulturunternehmen… Musik 3156000 0 Ausbe… 2020-04-29
3 Kulturunternehmen… Tanz/… 2730800 1517900 Ausbe… 2020-09-20
4 Kulturunternehmen… Musik 2722200 2091900 Ausbe… 2020-09-20
5 Kulturunternehmen… Musik 2519000 0 Ausbe… 2020-05-20
6 Kulturunternehmen… Klubs… 2391000 272200 Ausbe… 2020-07-20
7 Kulturunternehmen… Tanz/… 2368000 1566400 Ausbe… 2020-04-30
8 Kulturunternehmen… Klubs… 2159400 578400 Ausbe… 2020-04-13
9 Kulturunternehmen… Berei… 2049100 NA Ableh… 2020-09-15
# ℹ 2 more variables: Beschlussdatum <date>, ID <chr>In den folgenden Aufgaben wollen wir uns nur mit Beobachtungen beschäftigen bei welchen die Variable ‘Beschluss’ kleiner 100’000 CHF ist. Dazu wird der Datensatz gefiltert und als ein neues Objekt in dem RStudio Environment gespeichert. Ich habe den Code für dich vorbereitet.
Aufgaben
- Nutze die Daten im Objekt
corona_kultur_beschluss_geringum mit der Funktionggplot()einen Plot zu erstellen - Nutze die Variable ‘Beschluss’ für die x-Achse
- Nutze das Geom für ein Histogram für die Darstellung des Plots (Tipp:
geom_histogram)
Führe den Code aus und betrachte den Plot
- Ordne die Variable ‘Sparte’ der der visuellen Eigenschaft für Farben zu (Tipp: Schaue in Praktikum 3 oder 4 nach wie du es dort gemacht hast)
Führe den Code aus und betrachte den Plot
- Nutze Faceting und lege die Variable ‘Kategorie’ auf die Spalten (Tipp: Schaue in Praktikum 4 nach wie du es dort gemacht hast)
Führe den Code aus und betrachte den Plot
- Innerhalb der Klammern der Funktion
geom_histogram(), füge das Argument ‘binwidth’ hinzu uns setze den Wert auf 10000 (Tipp:binwidth = 10000). Was bewirkt dieses Argument?
Führe den Code aus und betrachte den Plot
- Füge einen Titel, einen Untertitiel und eine Bildunterschrift (caption) hinzu. (Tipp: Schaue in den Folien für Woche 2 nach)
🧶 ✅ ⬆️ Knit, commit, und pushe deine Änderungen auf GitHub mit der Commit-Nachricht “Füge Antwort für Übung 3 hinzu.” Achte darauf, alle geänderten Dateien zu committen und zu pushen, damit dein Git-Fenster danach aufgeräumt ist.
Gratulation! Du hast die Übungen abgeschlossen. Falls du noch Lust und Zeit hast, ist hier noch eine Bonusaufgabe.
Übung 4 (Bonus)
- Nutze das Objekt
corona_kulturund erstelle eine Säulendiagram (geom_bar) - Ordne die Variable ‘Sparte’ der visuellen Eigenschaft für Farben zu
- Ordne der x-Achse eine kategoriale Variable ‘Status’ zu (anstatt einer numerischen Variable ‘Beschluss’)
- Nutze Faceting und lege die Variable ‘Kategorie’ auf die Spalten
- Füge einen Titel, einen Untertitiel und eine Bildunterschrift (caption) hinzu.
- Ändere die Position der Legende auf den unteren Bereich des Plots (Tipp: Schau nach was wir in Übung 2 aus Praktikum 4 gemacht haben und ersetze ‘none’ durch ‘bottom’)
🧶 ✅ ⬆️ Knit, commit, und pushe deine Änderungen auf GitHub mit der Commit-Nachricht “Füge Antwort für Übung 4 hinzu.” Achte darauf, alle geänderten Dateien zu committen und zu pushen, damit dein Git-Fenster danach aufgeräumt ist.