Visualisierung ist ein wichtiges Werkzeug um Daten zu erkunden. In den seltensten Fällen kommen Daten jedoch in genau der Form welche benötigt wird um hilfreiche Visualisierungen zu erstellen. Es werden oftmals neue Variablen erstellt, Zusammenfassungen erzeugt, oder möglicherweise werden Variablen umbenannt und umgeordnet, damit effizient damit gearbeitet werden kann. Das R Package {dplyr} aus der Sammlung der {tidyverse} Packages ist genau für diese Arbeit gemacht wurden, welche auch oft als Data Tansformation, Data Manipulation, oder auch Data Wrangling betitelt wird.
Ziele
Diese Hausaufgabe hat die folgenden Ziele:
- Erfahrungen mit den Hauptfunktionen des
{dplyr}Package sammeln - Übungen aus dem Buch R for Data Science lösen
- Bei Fragen unseren Slack Channel für den Kurs nutzen
Erste Schritte
Öffne deine Email Inbox und suche nach der Email mit dem Link für das GitHub Repo zu dieser Hausaufgabe (ha-03-hallo-dplyr). Alternativ kannst du GitHub öffnen und in unserer GitHub Organisation nach dem Repo mit deinem Namen suchen.
Folge den Schritten aus Hausaufgabe 1 oder den Folien der Woche 2 um das GitHub Repo in deine RStudio Cloud zu clonen.
Packages
In dieser Hausaufgabe nutzen wir das {dplyr} Package und ein weiteres Daten Package names {nycflights13} um wesentliche Konzepte aus der letzten Lektionen zu üben. Das Package ist noch nicht installiert und ihr müsst dies in einem ersten Schritt selbst machen.
❗ 1. In der R Konsole: Installiere das {nycflights13} R package mit der Funktion install.packages("")
Data
Wir nutzen den Dataframe flights aus dem {nycflights13} R Package. Die Rohdaten für diesen Datensatz stammen aus dem United States Department of Transportation - Bureau of Transportation Statistics und wurden für das Buch R for Data Science aufbereitet und als Daten Package bereitgestellt.
Der Datensatz enthält alle 336.776 Flüge, die in 2013 von New York City abgegegangen sind. Der Datensatz beinhaltet 19 Variablen, welche im Detail der Hilfedatei beschrieben sind und mit ?flights aufgerufen werden können.
glimpse(flights)Rows: 336,776
Columns: 19
$ year <int> 2013, 2013, 2013, 2013, 2013, 2013, 2013, 201…
$ month <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, …
$ day <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, …
$ dep_time <int> 517, 533, 542, 544, 554, 554, 555, 557, 557, …
$ sched_dep_time <int> 515, 529, 540, 545, 600, 558, 600, 600, 600, …
$ dep_delay <dbl> 2, 4, 2, -1, -6, -4, -5, -3, -3, -2, -2, -2, …
$ arr_time <int> 830, 850, 923, 1004, 812, 740, 913, 709, 838,…
$ sched_arr_time <int> 819, 830, 850, 1022, 837, 728, 854, 723, 846,…
$ arr_delay <dbl> 11, 20, 33, -18, -25, 12, 19, -14, -8, 8, -2,…
$ carrier <chr> "UA", "UA", "AA", "B6", "DL", "UA", "B6", "EV…
$ flight <int> 1545, 1714, 1141, 725, 461, 1696, 507, 5708, …
$ tailnum <chr> "N14228", "N24211", "N619AA", "N804JB", "N668…
$ origin <chr> "EWR", "LGA", "JFK", "JFK", "LGA", "EWR", "EW…
$ dest <chr> "IAH", "IAH", "MIA", "BQN", "ATL", "ORD", "FL…
$ air_time <dbl> 227, 227, 160, 183, 116, 150, 158, 53, 140, 1…
$ distance <dbl> 1400, 1416, 1089, 1576, 762, 719, 1065, 229, …
$ hour <dbl> 5, 5, 5, 5, 6, 5, 6, 6, 6, 6, 6, 6, 6, 6, 6, …
$ minute <dbl> 15, 29, 40, 45, 0, 58, 0, 0, 0, 0, 0, 0, 0, 0…
$ time_hour <dttm> 2013-01-01 05:00:00, 2013-01-01 05:00:00, 20…Das Daten Package beinhaltet noch vier weitere nützliche Datensätze:
airlines: Beinhaltet den Namen der Fluggesellschaft für die Variablecarrieraus demflightsDatensatzairports: Beinhaltet Metadaten zu den einzelnen Flughäfen in der Variabledestaus demflightsDatensatzplanes: Beinhaltet Metadaten zu den einzelnen Flugzeugen in der Variabletailnumaus demflightsDatensatzweather: Beinhaltet stündliche meterologische Daten für die Flughäfen LGA (La Guardia), JFK (John F Kennedy Intl) und EWR (Newark Liberty Intl).
Du kannst mehr über die Datensätze in der Hilfedatei lernen oder diese mit der View() Funktion öffnen und erkunden.
Übungen
Aufwärmen 1
- Öffne die R Markdown Datei für die Übung
- Aktualisiere den YAML Header in dem du deinen Namen und das Datum hinzufügst
- Passe das Aussehen des Dokuments über die “Output Options” an (siehe Screenshots)
🧶 ✅ ⬆️ Knit, commit und push deine Änderungen auf GitHub mit einer Commit-Nachricht deiner Wahl. Achte darauf, alle geänderten Dateien zu committen und zu pushen, damit dein Git-Fenster danach aufgeräumt ist.
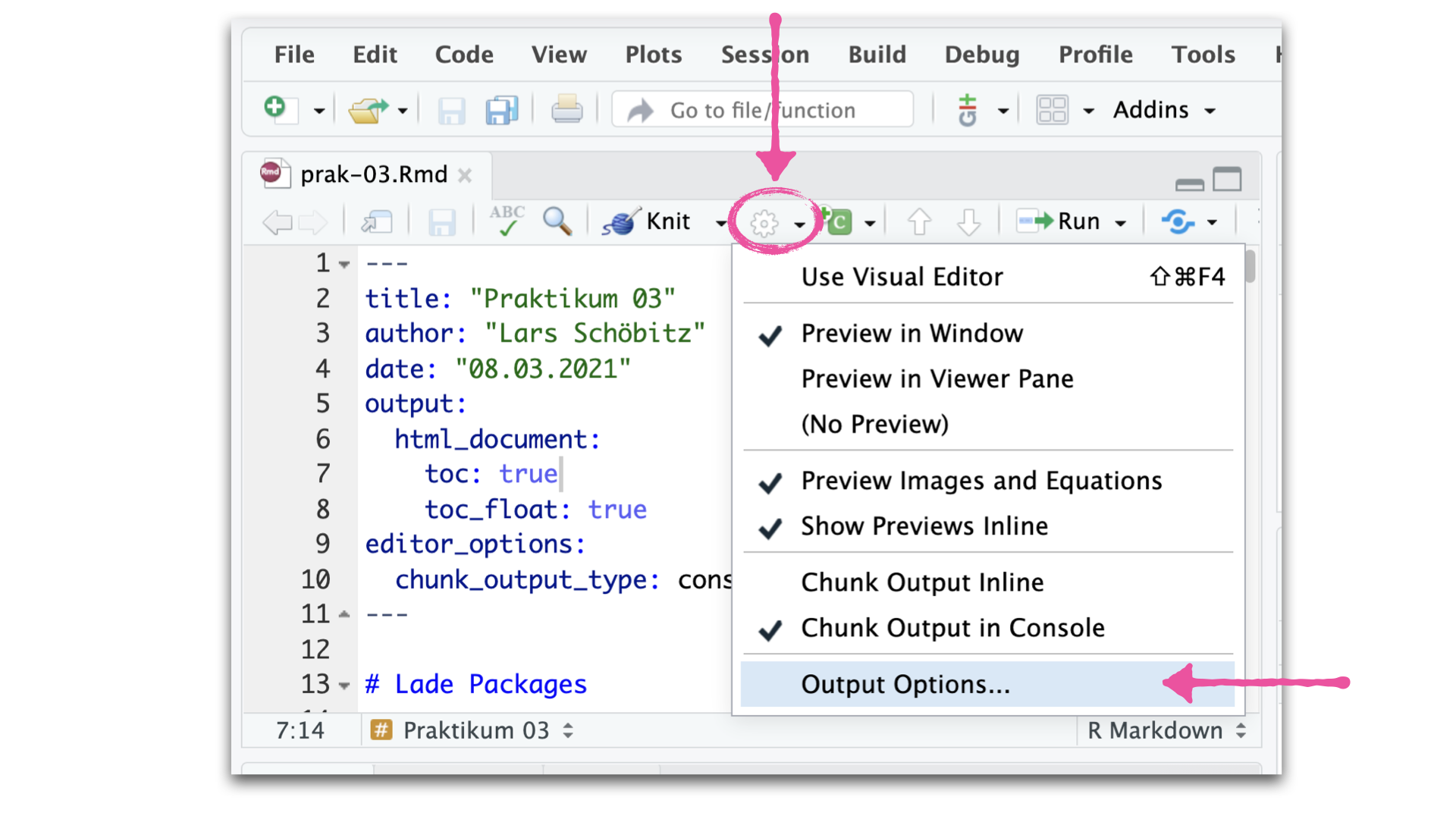
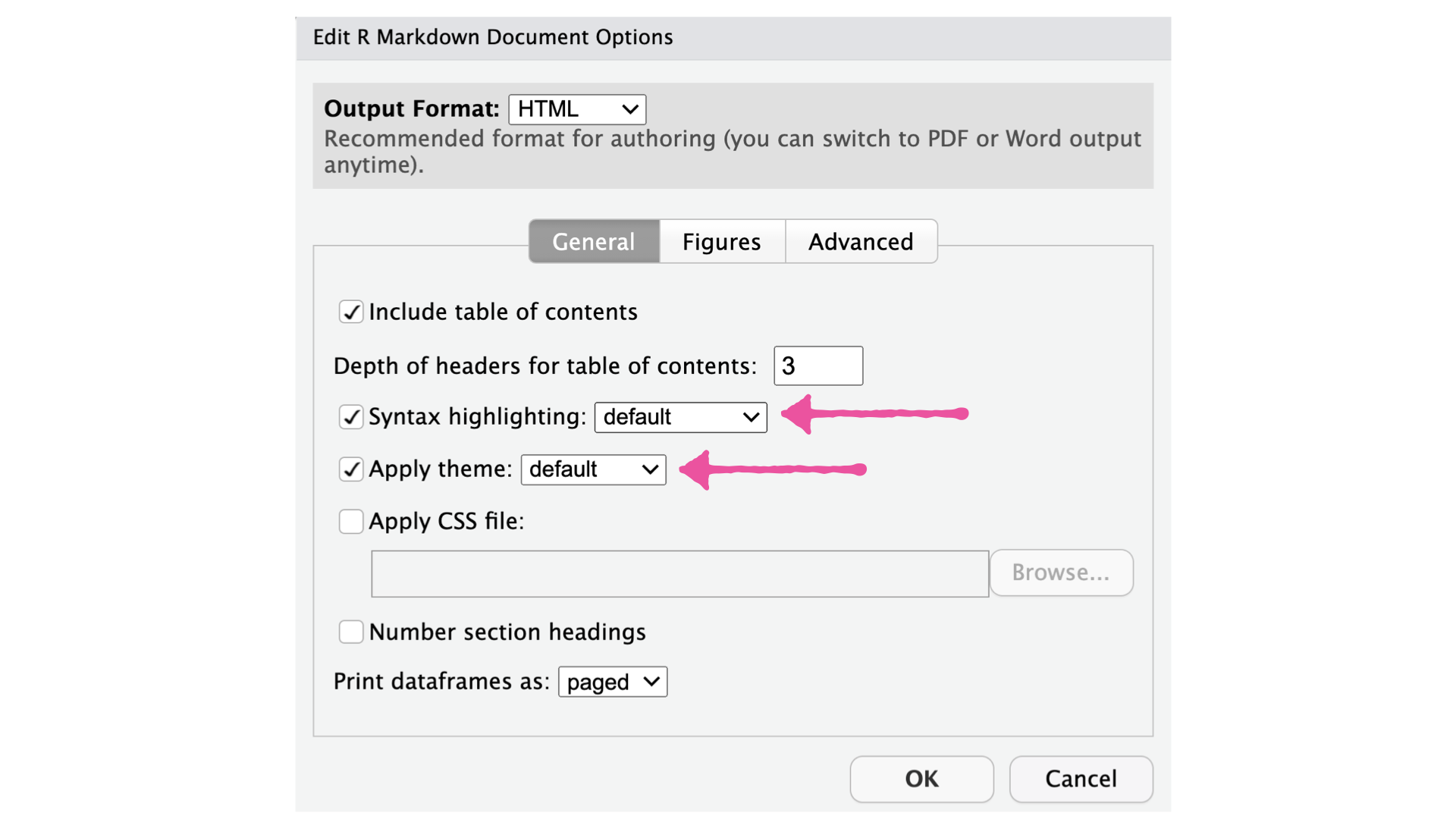
Übung 1 - dplyr::filter()
Lese das Kapitel 5.1 - Introduction aus dem Buch R for Data Science, mache dir Notizen und schreibe dir Fragen auf wenn du etwas nicht nachvollziehen kannst. Stelle deine Fragen in unserem Slack Channel für den Kurs.
Lese das Kapitel 5.2 - Filter rows with
filter()aus dem Buch R for Data Science, mache dir Notizen und schreibe dir Fragen auf wenn du etwas nicht nachvollziehen kannst. Stelle deine Fragen in unserem Slack Channel für den Kurs.Arbeite durch die Übungen aus Kapitel 5.2.4 - Exercises. Stelle Fragen in unserem Slack Channel für den Kurs.
🧶 ✅ ⬆️ Knit, commit und push deine Änderungen auf GitHub mit einer Commit-Nachricht deiner Wahl. Achte darauf, alle geänderten Dateien zu committen und zu pushen, damit dein Git-Fenster danach aufgeräumt ist.
Übung 2 - dplyr::arrange() - Noch nicht im Kurs behandelt
Lese das Kapitel 5.3 - Arrange rows with
arrange()aus dem Buch R for Data Science, mache dir Notizen und schreibe dir Fragen auf wenn du etwas nicht nachvollziehen kannst. Stelle deine Fragen in unserem Slack Channel für den Kurs.Arbeite durch die Übungen aus Kapitel 5.3.1 - Exercises. Stelle Fragen in unserem Slack Channel für den Kurs.
🧶 ✅ ⬆️ Knit, commit und push deine Änderungen auf GitHub mit einer Commit-Nachricht deiner Wahl. Achte darauf, alle geänderten Dateien zu committen und zu pushen, damit dein Git-Fenster danach aufgeräumt ist.
Übung 3 - dplyr::select() - Noch nicht im Kurs behandelt
Lese das Kapitel 5.4 - Select columns with
select()aus dem Buch R for Data Science, mache dir Notizen und schreibe dir Fragen auf wenn du etwas nicht nachvollziehen kannst. Stelle deine Fragen in unserem Slack Channel für den Kurs. Es werden dir sogenannte “helper functions” vorgestellt, welche wir im Kurs noch nicht behandelt haben. Folgt dem Text und versucht zu verstehen was diese bewirken.Arbeite durch die Übungen aus Kapitel 5.4.1 - Exercises. Stelle Fragen in unserem Slack Channel für den Kurs.
🧶 ✅ ⬆️ Knit, commit und push deine Änderungen auf GitHub mit einer Commit-Nachricht deiner Wahl. Achte darauf, alle geänderten Dateien zu committen und zu pushen, damit dein Git-Fenster danach aufgeräumt ist.